spark submit 任务出现的error
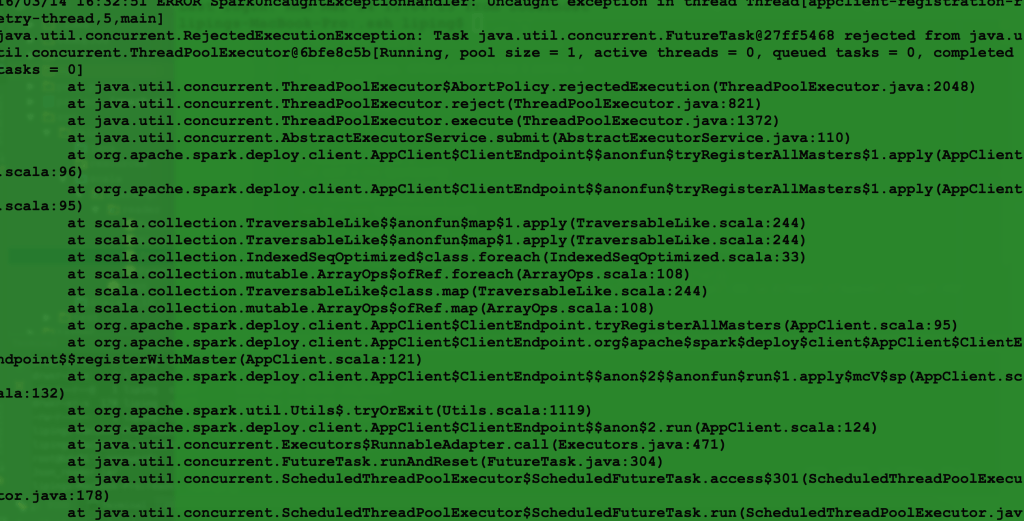
解决办法
提交命令
|
|
该命令之前master直接写的IP,所以导致这个问题,换成hostname就不会报错了。
提交命令
|
|
该命令之前master直接写的IP,所以导致这个问题,换成hostname就不会报错了。
关于什么是lineage dependency,可以参考Spark Programming Guide中详细讲解RDD的部分,RDD是spark的数据结构,它主要有两部分,五个components:
这样的数据结构设计跟其lazy computation的特性是一脉相承的。当我们写一个迭代的算法,其中很典型的依赖有这样两种:
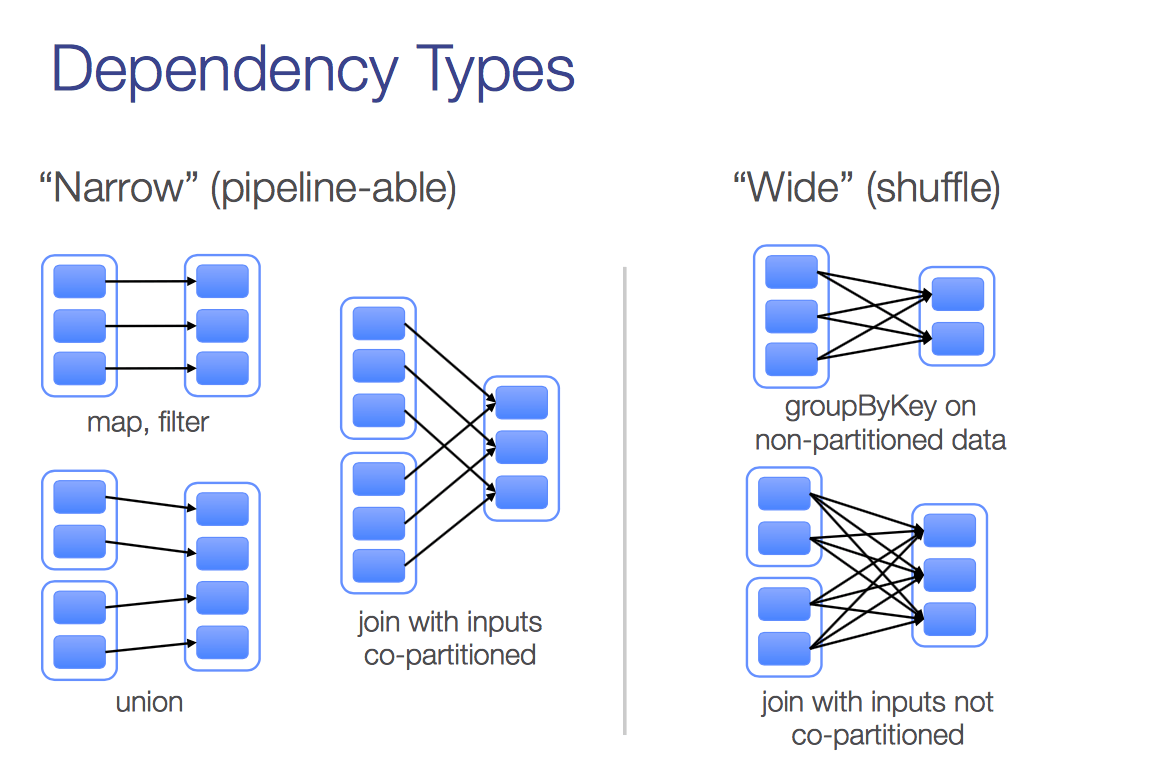
在一次迭代中,往往都需要有至少一次action。没有action也不是不行,这种情况在迭代不需要额外计算条件的情况下,或者说就是设置迭代多少次终止的情况下,理论上是可以的,就是把所有的的计算都放在最后风险很大,至于为什么以后我试试可以具体说说。假设一次迭代中只有一个action, action就是让RDD中得lineage开始计算的一组API(比如Reduce, count等), 每一个action都会有一个stage,而每个stage都scheduler调度的task(如下图), 这些tasks在各个excutors上运行。
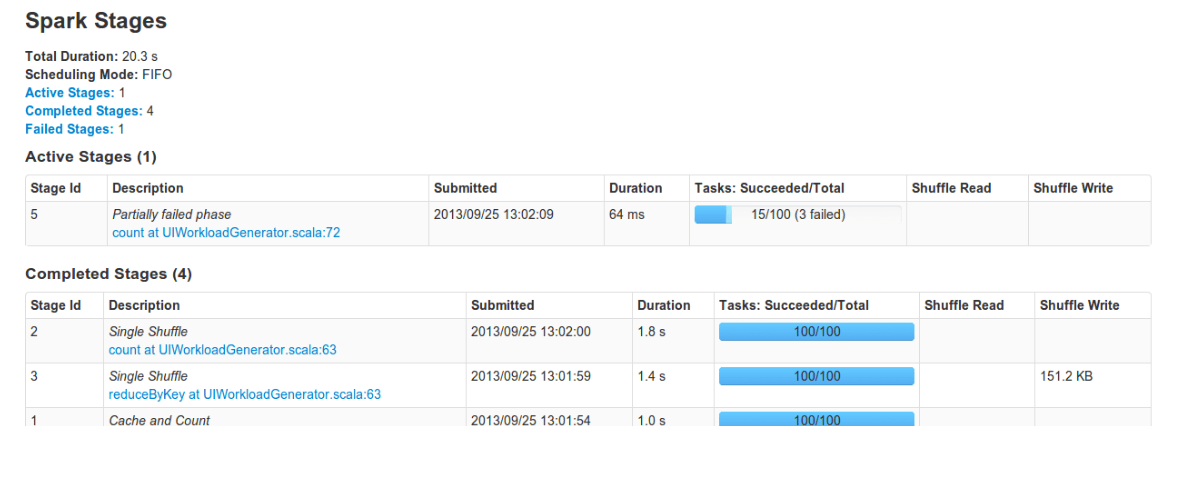
迭代算法一般可以通过dashboard看到如下的UI,我经常会遇到每轮迭代时间越来越长的情况,开始的时候我特别纳闷,既然我每轮迭代都会进行合理的cache以及unpersisit,也不会过多的使用内存,每轮迭代的任务也是一模一样的,为什么时间上差别如此之大,这个疑问一直持续到有老师建议我在物化RRD之后设置checkpoint到HDFS我仍然没有想通。设置checkpoint确实是一个改善迭代时间越来越长问题的有效策略,现在想来跟自己对下层系统了解太少不无关系。
当我昨天看到腾讯王老师的一篇介绍分布式机器学习框架–分布式机器学习的故事的内容后豁然开朗,这篇文章中提到了Fault Recovery对于一个分布式平台的重要意义,里面着重介绍了对于MPI而言,因为其Fault Recovery不方便,所以需要经常做checkpoint使得MPI框架可以做到容错。相比之下,spark的lazy computatation以及保存历史的lineage都天然地保证了其可以很方便的进行Fault Recovery。这让我想到在大的数据集上进行迭代,迭代的时间理论上是不应该越来越长的,但是其错误恢复却是越来越长就可以理解了的,任何一个task的failure都会造成从头开始计算,尤其是开始的时候还unpersist了认为没用的一些中间数据。
假设一个task不出错的概率是$p$,如果一次迭代有$N$个task, 那么每次迭代不用进行错误恢复的概率就是$p^N$, 迭代到第$K$次第一次错误恢复的概率就是一个几何分布,概率为$p^{N \times (K - 1)} \times (1 - p^N)$。从这个概率上看,也可以看出迭代到后来不需要Fault Recovery的概率非常之低。
设置checkpoint也是有代价的,如果每次都要读写HDFS,每次迭代的时间虽然不会变化,但是跟之前还是要慢很多的。这里面就需要一个trade off, 这里需要考虑集群性能,以及数据集大小,是错误恢复需要的时间多还是读写HDFS需要的时间多(从dashboard上可以看出来),我在写pagerank的时候采用的是前五次迭代都不要checkpoint,后面每隔一次checkpoint的策略。
在plugins.sbt文件中添加Assembly插件, addSbtPlugin(“com.eed3si9n” % “sbt-assembly” % “0.11.2”)
创建一个参数类,ParaConfig
|
|
|
|
打包过程中会出现很多冲突,可以在.sbt中依赖的包后面加上provided,一来不用解决冲突,另一方面也会减少包的容量。
Assembly打包成功并不是万事大吉了,待运行的时候可能会遇到NoSuchMethodError这样的错误。
这个错误是因为scala 的版本问题造成了,将build.sbt中scala的版本写成2.10.4这个ERROR就可以避免。至此就没有大的问题了。
最近在写一个KShell 算法,使用的是跟pagerank一样的数据集twitter,算法在小数据集上都没有问题,但是在集群上每次算法跑到90%的时候都出现stackoverflow,虽然之前写pagerank有经验,设置了checkpoint,但是跑了几次仍然是老毛病。
在侯哥的帮助下,我发现设置checkpoint也有没用的时候,RDD不仅有个checkpoint,可以将RDD的lineage 截断,也有个函数isCheckPointed()来检测该RDD是否checkpoint成功了么。现在记录下这个很容易出错的大坑,积点儿人品。
|
|
这样返回checkpoint没有成功,因为之前g已经被物化了。
|
|
这样返回checkpoint仍然没有成功,因为之前g只在checkpoint之后物化了vertices,edges没有物化,所以整个图仍然没有物化。
work的checkpoint是这样的:
|
|
只有在checkpoint之后,物化vertices以及edges,整个图的checkpoint才会成功。
最后总结一下,对于普通RDD,要像成功checkpoint,需要之前没有物化,chekpoint后物化它,对于像grpahx 中grpah这样的数据,不仅仅要物化vertice,还要物化edges,物化triplets没用,至于为什么物化triplets不行,我也没找到合理的解释。
前一段时间参加一个电信举办的天翼杯大数据比赛,让我好生反思了自己前半年的工作,以至于当天晚上我难过得失眠了半宿。这半年我总共写了五个分布式算法,涉及了图计算、矩阵分解、监督学习,从数量上讲不算少,小辉老师跟我们说我们的BDALib已经有30000多行代码了,考虑到我的贡献,5000行应该还是有的,scala本身是比较精炼的语言,另外每次写完还有code review,我对这个数量还是挺满意的。可是当我需要用到这些算法的时候,我竟然觉得自己写的代码不可靠,要不是数据量达到一定规模,我是决计不愿意用自己写的算法的。同样是实现了Factorization Machine, 尽管我更清楚自己写的算法的逻辑,但是我还是更愿意用LibFM。当我抱着试试的态度用我的算法包跑上G的训练数据的时候,中途果真是崩溃了,我感觉我被这意料之中的事实甩了一记响亮的耳光。
当天晚上我就一直反思我写BDALib的意义,从我的角度而言,我深入地知道了这些算法的逻辑,更加熟悉了spark以及Pregel等分布式系统以及分布式框架的使用,知道怎么优化算法,提高可扩展性,用在年末工作汇报大boss的话说,我的工作对自己的提升是很明显的。可是,我也觉得写了若干算法,只有为数不多的能经得起上亿规模数据,鲁棒性不可知,也是件极其悲哀的事儿。我想如果有一天别人问我,我的那些基于spark平台的机器学习算法如何的适合,我可以拍拍胸脯告诉他,如果哪一天在一个场合可以用到她,我会毫不犹豫的选择自己的算法包,那样我就知足了。写多了那种写完了过两天就没用的垃圾代码,可想而知内心对自己的鄙视。当自己在不断成长地同时,这样的事实真是让我越来越不能淡定了。
这里我想起了自己曾经写的一个感悟。
大部分事儿,不好好坚持下来意义不大,比如学了一年就没怎么用心的摄影,比如偶尔想起来会去游泳健身,比如一时兴起才会看看的严肃书籍,并没有多大用;因为我不好意思说自己会摄影,只好说我会用单反,我也不好意思说我健身,或者我的身体并没有很大的改善,因为我并不怎么健身;我不好意思说我了解政治,通晓历史,因为我只是知道一些边角料罢了。
当我离找工作的日子越来越近,当知道我不懂得越来越多,这个时候我更希望自己能坚持自己的初衷,写一个鲁棒、性能不错、可扩展性强的分布式算法的意义远比草率地写好多坨垃圾代码强的多。写代码真的是个精雕细琢的活,即使是写好了,测试也是件不容忽视的过程。想想当初我跟大boss信誓旦旦地说我们的BDALib有code review,有算法的设计文档,有单机版本,有详细的测试报告,有友好的API,这是多么的naive。 单元测试有了,可是有实例测试有几个,有小数据集中等数据集测试,上亿规模的数据集测试过了么?做工程,学习的过程已不仅仅是掌握其中的技术原理,更要紧的是要明白做工程的态度,做精致做细节。路还有很长,踏踏实实,不骄不躁,莫要心大,以此自勉。
在我写这篇自省的博客的时候,队友告诉我,我们初赛进入了前十,我们用了十天的时间达到了这个效果,还是非常欣慰的。另外这也给我一个警醒,趁着第二赛季的大数据还没来,早点提高BDALib中算法的鲁棒性。
当我写分布式算法的时候,我不是在想我要学会用spark,不是在想搞懂这个算法,我在想我要搞一个“简单可依赖”的分布式算法包。
说来惭愧,之前一点没有用过数据库的调用接口,这一次为了是实现一个ETL的功能,只能自己去摸索解决这方面的办法。好在网上资料多,解决问题的能力也在不断进步。但是用spark读异源数据的经验与分享还是不多,索性记录下我读Hive 以及mysql的经历。
Hive中我主要是参考的spark 的官方文档关于hive的使用方法来的。
|
|
我使用的是sbt来配置的依赖,其中依赖为
|
|
当我在服务器上执行上面的代码的时候, 开始一直报org.apache.hive.conf 找不到,最后我的处理办法是将hive的包全部加到spark的运行环境中,当然这也是下策,毕竟包很多。之所以这样主要原因应该是spark集群是编译好再部署的而不是用源码编译的,没有将hive的lib加入到spark的classpath 下,我试过用源码编译加了-Phive就有效的规避了这个问题。
这个问题解决完之后就遇到了下面的情况: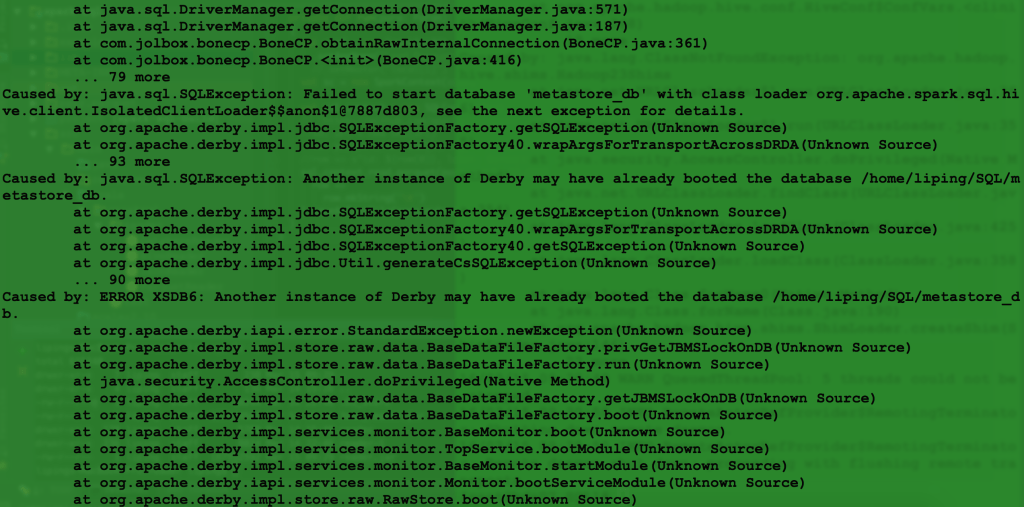
我google以后发现大概原因是如果不配置hive,hive默认的metastore是derby,然而derby的是不允许多个任务同时访问derby数据库的,这个问题遇到的人很多,大概分成两种解决思路,一种是配置derby 的network service 的,一种是修改hive的配置文件,配置hive的hive-site.xml文件,使得hive的metastore是mysql.
|
|
另外配置完了hive-site.xml后还需要将该文件放在spark 的conf目录下,这样spark 才会读到hive的配置参数。
如果环境配置好了,用spark sql来读hive table是一件特别惬意的事儿。
|
|
spark 通过JDBC连接Mysql读取其中table也很容易,重要的是设置好以下参数
url mysql数据库的url jdbc:mysql://MysqlServer:3306/DatabaseName
driver: java 连接mysql的驱动,这里我遇到一个坑,就是当我下载了mysql-connector-java-5.1.35-bin.jar的时候,总是出现 “no suitable driver found”,这个error 我待会细说。
另外加上访问数据库的用户名以及密码。
下面这条语句就可以访问mysql中已经存在的table。
|
|
spark 通过JDBC连接Mysql,如果执行查询计算等操作有两种方式:
一种是给mysql server 传一个sql 语句,这样最后返回的dataframe就是查询的结果
|
|
另外一种是将load的dataframe注册一个临时表格,执行查询操作, 具体方法使用如下:
|
|
一般有三个原因导致出这个错误:
沿着前人的步伐走下去总是比较容易的,想当初刚用spark写算法的时候,连使用idea打包失败这类错误都有同学帮助自己解决掉,以至于最后我发现自己独立解决问题的能力越来越差,如果一个问题除了google周围没有任何人能给与援手,自己会在上面被困好久。从年前一个人部署Zeppelin到现在解决这些问题,我深刻地感受到如果自己想独当一面首先得有resolve error的能力,如果要想有resolve error的能力,信心比其他的更加重要,多少次被困住并不是多麻烦的问题,而是内心的恐惧。我想起《暗时间》中的一句话:
过早退出往往在于对于未来的不确定性,对于投资时间最终无法收到回报的恐惧,感受到的困难越大,这种恐惧越大,因为越大的困难往往暗示这个任务需要投资的时间越多。所以我们都是直觉经济学家,当我们“畏难”的时候,其实我们畏惧的不是困难本身,而是困难所暗示的时间经济学意义。
一言以蔽之就是不自信自己能解决问题嘛,作为一个程序员,解决问题简直就是家常便饭,切不可因为心里的懊恼伤害了前进的动力。我也开始发现这里的一些问题,之所以被卡很久,一方面是自己不能冷静思索,更重要的是自己对专业素养不够。这次感慨颇深,索性记下来自勉。
最近的工作一直围绕着怎么灵活地将异源数据导入我们的图形化机器学习平台中,也就是ETL中的最后一步Load,其间因为不了解hive浪费了好多时间,但是好歹最近实现了这些过程。现在记录下使用spark跟其他源数据交互的一些经验。
spark跟mysql交互就跟java与mysql数据库交互之前需要建立连接一样,首先需要提供database, table, username, password等,建立连接以后spark有一个API可以直接将mysql中的表格转换成dataframe。
|
|
dataframe不仅可以完整地保存mysql的table中的数据信息,还可以保存table的schema信息,事实上dataframe就是一种类似于table的数据结构,可以支持查询以及其他的一些数据库操作。
因为dataframe保存了schema信息,所以可以将该数据保存成不同格式的文件。
|
|
这里读hive不是跟spark on hive,如果是这样的话,整个事件就简单的多,都不用连接,直接就可以读取hive的table。关于hive on spark 的配置,需要使用spark的源码进行编译,编译的时候加上-Phive, -Pthriftserver。
最近调研kaggle比赛的一些情况,因为比赛数据集往往很大,每次通过浏览器下载再上传到服务器是一件十分费力的一件事情,所以我想怎么用wget来直接进行下载。因为kaggle比赛是一个需要用户名登陆,以及含有各种协议的网站,如果不通过浏览器下载wget只会下载一个html的页面。
怎么通过模拟浏览器来下载这个数据集呢,我查了好多地方,发现wget有个参数 –load-cookies 可以模拟浏览器下载东西。
打开google浏览器More Tools->Extensions->More Extension, 进入Chrome Web Store下载一个插件cookies.txt.
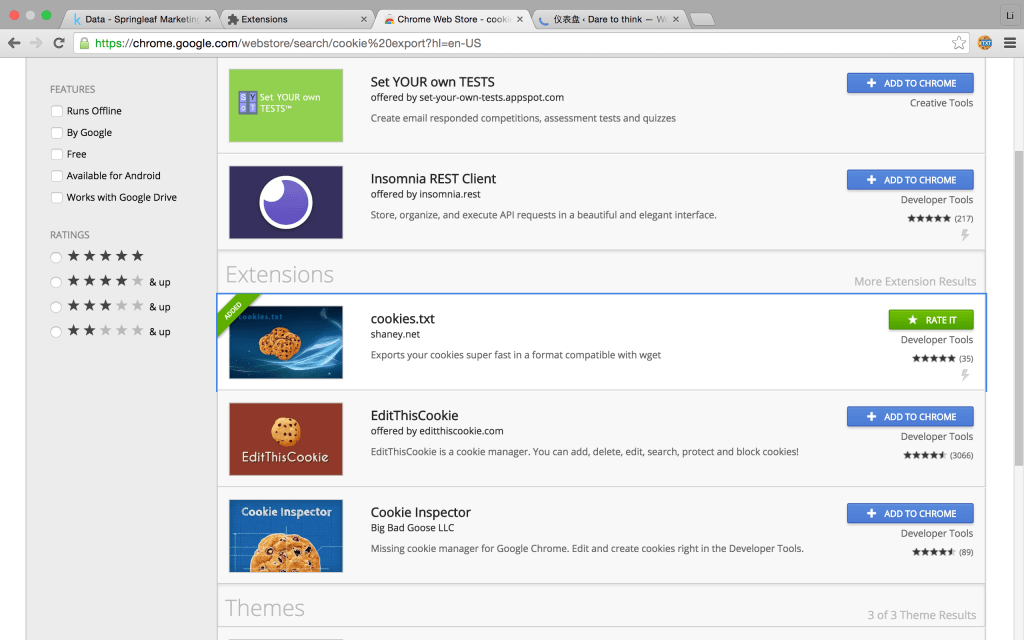
安装完成以后打开该下载页面,就可以看到cookie文件
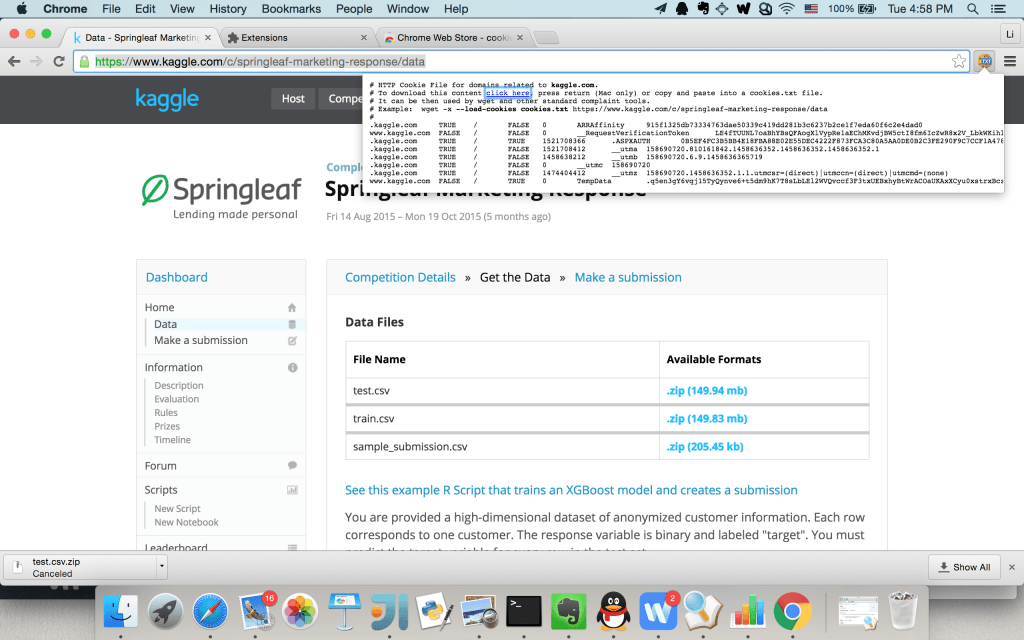
复制cookie信息到一个文件cookies.txt中,使用下面的命令就可以顺利下载了。
|
|
|
|
|
|
|
|
|
|
|
|
|
|

hive的动态连接还存在一定问题,这主要是对hive缺乏必要的了解导致的,接下来会看看spark-sql跟hive是怎么整合的,把这个问题给解决掉。