lineage dependency
关于什么是lineage dependency,可以参考Spark Programming Guide中详细讲解RDD的部分,RDD是spark的数据结构,它主要有两部分,五个components:
- lineage info: Partitions, dependencies, computation(计算逻辑,比如map,filter,join).
- optimization info: partitioner, preferred locations.
这样的数据结构设计跟其lazy computation的特性是一脉相承的。当我们写一个迭代的算法,其中很典型的依赖有这样两种:
narrow dependency && wide dependency
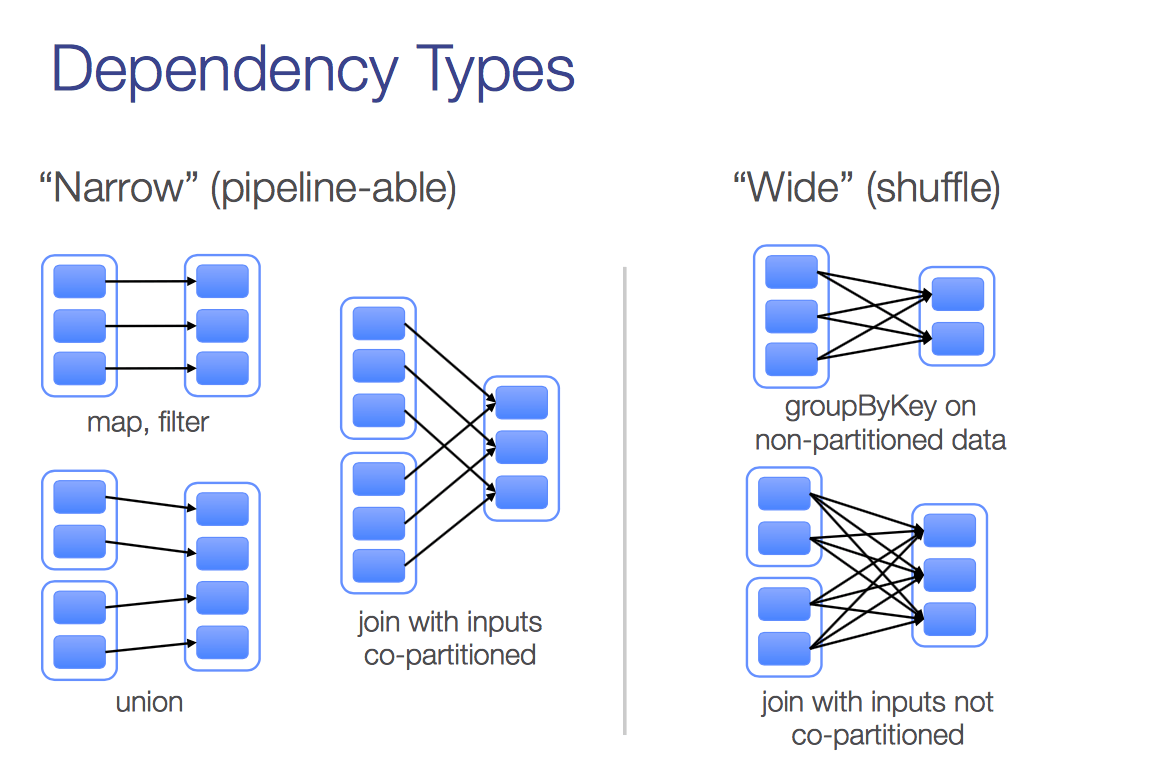
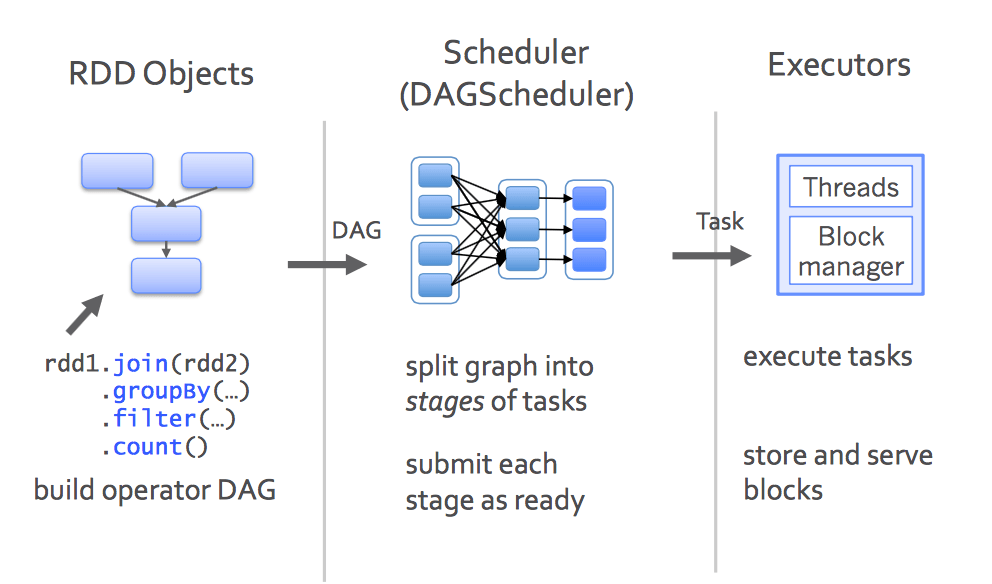
Stage && task
在一次迭代中,往往都需要有至少一次action。没有action也不是不行,这种情况在迭代不需要额外计算条件的情况下,或者说就是设置迭代多少次终止的情况下,理论上是可以的,就是把所有的的计算都放在最后风险很大,至于为什么以后我试试可以具体说说。假设一次迭代中只有一个action, action就是让RDD中得lineage开始计算的一组API(比如Reduce, count等), 每一个action都会有一个stage,而每个stage都scheduler调度的task(如下图), 这些tasks在各个excutors上运行。
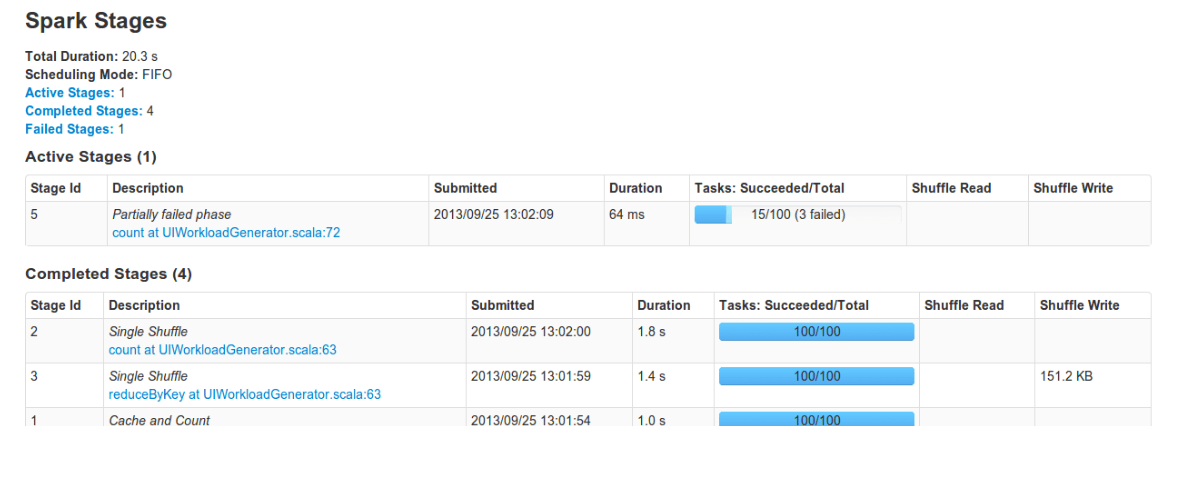
迭代变慢
迭代算法一般可以通过dashboard看到如下的UI,我经常会遇到每轮迭代时间越来越长的情况,开始的时候我特别纳闷,既然我每轮迭代都会进行合理的cache以及unpersisit,也不会过多的使用内存,每轮迭代的任务也是一模一样的,为什么时间上差别如此之大,这个疑问一直持续到有老师建议我在物化RRD之后设置checkpoint到HDFS我仍然没有想通。设置checkpoint确实是一个改善迭代时间越来越长问题的有效策略,现在想来跟自己对下层系统了解太少不无关系。
当我昨天看到腾讯王老师的一篇介绍分布式机器学习框架–分布式机器学习的故事的内容后豁然开朗,这篇文章中提到了Fault Recovery对于一个分布式平台的重要意义,里面着重介绍了对于MPI而言,因为其Fault Recovery不方便,所以需要经常做checkpoint使得MPI框架可以做到容错。相比之下,spark的lazy computatation以及保存历史的lineage都天然地保证了其可以很方便的进行Fault Recovery。这让我想到在大的数据集上进行迭代,迭代的时间理论上是不应该越来越长的,但是其错误恢复却是越来越长就可以理解了的,任何一个task的failure都会造成从头开始计算,尤其是开始的时候还unpersist了认为没用的一些中间数据。
假设一个task不出错的概率是$p$,如果一次迭代有$N$个task, 那么每次迭代不用进行错误恢复的概率就是$p^N$, 迭代到第$K$次第一次错误恢复的概率就是一个几何分布,概率为$p^{N \times (K - 1)} \times (1 - p^N)$。从这个概率上看,也可以看出迭代到后来不需要Fault Recovery的概率非常之低。
经验之谈
设置checkpoint也是有代价的,如果每次都要读写HDFS,每次迭代的时间虽然不会变化,但是跟之前还是要慢很多的。这里面就需要一个trade off, 这里需要考虑集群性能,以及数据集大小,是错误恢复需要的时间多还是读写HDFS需要的时间多(从dashboard上可以看出来),我在写pagerank的时候采用的是前五次迭代都不要checkpoint,后面每隔一次checkpoint的策略。