背景
模型融合对于提高模型结果是一种非常有效又非常便捷的做法,虽然这个步骤一般发生在最后关头,但是不影响它给广大的参赛者带来一次又一次惊喜。调研Kaggle比赛以来,我一直看到优胜者们三番两次说自己的模型在最后怎么融合,怎么取得了不错的结果。当然融合是很重要,但是再好的融合也离不开单个模型的效果。这个是后话,这里我简要介绍下上面Bagging、Blending、Boosting and Stacking四个概率的区别于联系。
Ensemble
融合的优点
- 从统计模型的⾓角度来讲,单个模型可能会因为误选导致性能不好
- 从计算⾓角度讲,学习算法往往会 陷⼊入局部最⼩小化,局部极⼩小点的 泛化性能可能很糟
- 从表⽰示⽅方⾯面来看,某些学习任务 的真实假设可能不在当前学习算 法所考虑的假设空间中,此时使 ⽤用单学习器肯定⽆无效
两阶段
我们一般提到的模型融合也叫Ensemble,包含这几个阶段:
- 分不同的训练集
- 单个模型训练
- 多个模型的融合
区别
Bagging
- 多模型的训练相互独立,可以并行
- 元模型都是由同种算法生成的,也叫同构融合
- 主要利用样本的多样性来增加模型的多样性
- 典型例子是随机森林算法(random forest), 但是RF中不光存在样本采样还会有特征采样。
Blending
- 多模型的训练相互独立,可以并行
- 元模型都是由同种算法生成的,也叫异构融合
- 主要利用样本的多样性来增加模型的多样性
Boosting
- 模型之间的训练是相互关联的,前一个模型的训练结果会影响后一个模型训练样本的权重。模型之间不能并行。
- 模型之间不能不能异构融合
- Boosting最后会根据模型的误差等信息来进行融合,不能采用其他的融合方法
- 典型代表是(Adaboost, GBDT)
Stacking
- 将元模型的学到的结果再学习一遍
- 元模型可以使用不同的训练方法
- 两层学习
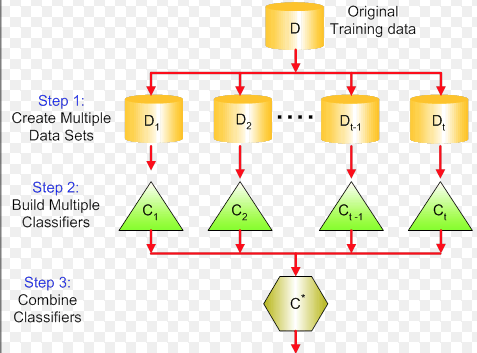
Bagging、Blending、Boosting发生在元模型训练阶段,都是元模型训练的一些策略
Stacking发生在模型融合阶段,就是当元模型都训练完毕,如何将最后的结果合并成一个最终的结果
Bagging和Blending的主要区别就是体现在元模型的结构上,前者是同构的,后者是异构的
强调一点,Boosting本身就是元模型的线性组合,不存在融合策略,这个很容易理解。Adaboost的最终模型就是若干个模型的线性组合
模型融合的目标
模型融合的终极目标是在不降低单个模型的性能的基础上提高模型之间的多样性,也就是通常说的降低模型的相关性。
通常模型的相关性一般这样衡量,将两个模型同时预测同样一份validation data, 最后根据混淆矩阵,然后可以计算相关系数来度量两个模型间的相似性。
提高模型多样性
- 样本扰动
- 特征扰动
- 参数扰动
适用场景
- 样本扰动适合样本比较多的模型,样本扰动不至于对单个模型影响太大,比较常用的两种样本扰动方式是Bootstrap(重复采样)以及K-折交叉验证。
- 特征扰动,适合特征比较多而且特征存在很多冗余的情况,特征抽样对单个模型的调参要求很高,因为很容易因为特征抽样使得单个模型的表现不好。
- 参数扰动适合模型参数比较多的情况,采用不同的初始化方式也算是参数扰动的一种,比较适合对初始化很敏感的模型。